vREalize operations: troubleshooting
Project overview
My Role
I was the design lead and main designer for this project. During the research phase of the project, I had support from a junior designer to prepare prototypes for research. I defined a vision, created storyboards, conducted user research sessions, created designs, and collaborated with engineering to implement the designs.
THE PROCESS
For the project, we used the following process:
1) Creating a Vision
2) Defining the Scope
3) User Research and Analysis
4) Design Ideation and Iteration
5) Implementation
The PRODUCT
vRealize Operations Manager is a tool used by virtual infrastructure teams to manage, monitor, troubleshoot, plan, and optimize their virtual cloud environments.
The Challenge
One of the main reasons our users come to vRealize Operations Manager is to troubleshoot issues; however, today, the process is very manual and time-consuming. For this project, we want to help them find the root cause more easily, so they can resolve their issues as quickly as possible.
the importance of troubleshooting
Troubleshooting is one of the most important reasons our users, virtual infrastructure admins (I’ll call them VI admins from here on out), come to vRealize Operations Manager. The VI admins are responsible for ensuring applications are receiving the CPU, memory, and storage resources they need to run properly.

When something goes wrong, they need to solve it as soon as possible. If they don’t, this could mean downtime on important business applications, which results in monetary loss for the company. Often, our users are measured by their MTTR (mean time to resolution, how quickly they can fix the problem) or MTTI (mean time to innocence, how quickly they determine the virtual infrastructure team is not the cause of the problem).
Creating a Vision
While at VMware, I’ve worked on a few troubleshooting projects; however, most of them felt more like incremental improvements rather than a longer term vision of how we can drastically improve how users do troubleshooting.
With my expertise in the user space and through collecting feedback from internal stakeholders to better understand the market and our business goals, I created an end-to-end vision on what troubleshooting can look like in the future. This ideal story is told in 3 acts, with time passing in between each as our users refine their processes and gain trust with the system.
In order to convey the story, I created hand-drawn storyboards. You can get a sneak peek at some of them below along with a summary of each act.
Act 1: Efficient and Collaborative Troubleshooting
In the first act, the VI admin receives a ticket regarding an application issue. The system gathers relevant evidence based on the scope of the issue and presents that to the VI admin in a consolidated workspace. The VI admin is able to determine the root cause of the problem and takes action to resolve the issue.

Act 2: Intelligent TRoubleshooting
Some time passes, and we arrive in the second act. Over time, the system learns what kinds of problems are tied to what types of resolutions. It auto-detects issues and proactively notifies the VI admin before anything goes seriously wrong. The system then provides an intelligent recommendation to resolve the issue. The VI admin approves the action, and the issue is resolved.

Act 3: Self-Driving Operations
Some more time passes, and by the third act, most of the issues are now auto-resolved. Through confirming over time that the system recommendations have successfully resolved issues, the VI admin has built up trust in the system to automatically run actions when issues arise. The VI admin is able to review what types of actions are being run and can manage automation settings. The overall IT team runs more efficiently.

Defining the scope
I got the opportunity to share the vision with upper management and got buy in to work on it for the coming release. We only had a few months, so we had to figure out what the road map for this will look like. We had to take into factors such as team bandwidth and existing vs required technical functionality. I worked with the product managers to come up with a plan and agreed that a reasonable scope for the coming release would be Act 1.
From there, we’ll continue to build on top of it release after release and ensure the engineering teams start thinking about what type of machine learning and AI would be required to make this come to life.
user RESEARCH and analysis
To make sure the scope had viable user value and impact, we conducted a series of user research sessions.
We created storyboards and quick concepts to test out some scenarios with users at VMworld, VMware’s annual virtualization and cloud computing conference.
Here is a sample storyboard created to set up context and validate a realistic troubleshooting scenario our users might encounter:

When presenting this scenario, there were a lot of head nods in every session we ran; the scenario was realistic and resonated with our users.
We also validated the following pain points:
Information is scattered throughout the product and requires a lot of context switching.
It’s difficult to understand extent of the problem.
It’s tedious to figure out what’s changed that could have caused the problem.
In addition to confirming the pain points, we also gained these insights:
A troubleshooting tool independent of a ticketing system is still useful. (We had pushback from some internal stakeholders that users wouldn’t use our tool on top of their ticketing system but this was not true.)
Environment scope and time are the most important inputs to gathering evidence.
A topology view of objects is super beneficial because users are manually building that relationship in their head.
Below you can see some of the design concepts we ran by users and a snippet of the data we gathered:

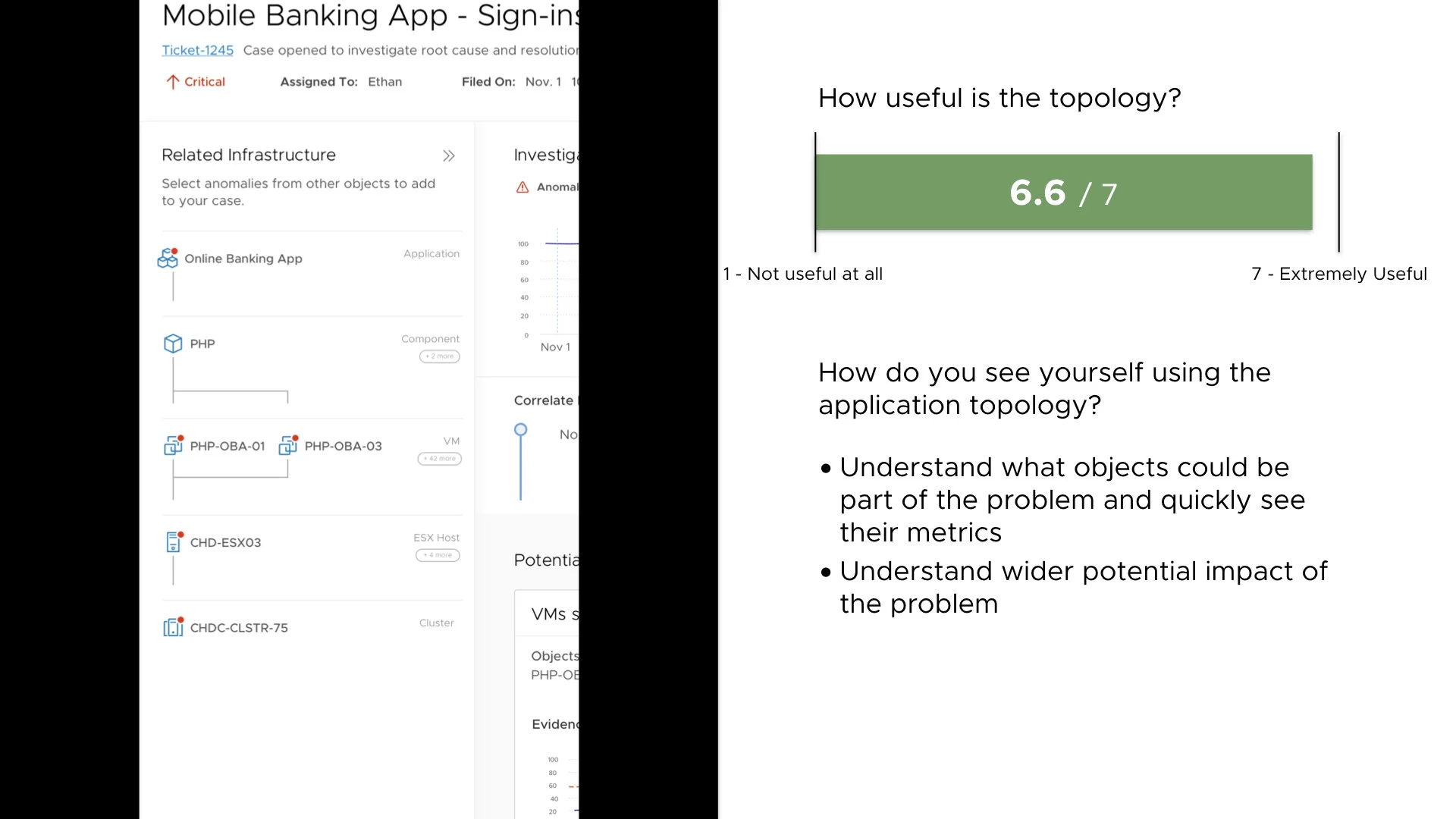
Overall, we found users were very excited about this new flow and functionality.
Design Ideation and Iteration
When a VI admin is notified of a problem, the most crucial questions they need to answer are:
What happened?
When did it happen?
What changed during this time?
Often, troubleshooting starts when they receive a call, ticket, or alert about a problem. They’ll know where it happened, so they’ll have the name of the object (application, virtual machine, server, etc). They’ll also know approximately what time the issue occurred.
Inside vRealize Operations Manager, we want to provide the user information about objects related to the starting object along with changes (events, property changes, anomalous metrics) that will help point the VI admin to the root cause of the problem. With this, I defined an ideal workflow:
There are two starting points for this workflow. Starting Point 1 is where the system detects a threshold violation, and the VI admin receives an alert from vRealize Operations Manager. Starting Point 2 is where a VI admin gets a ticket or call that something has happened; in this case, they would start by searching for the object.
Initial Brainstorming
Considering the quick concepts from VMworld and the flow above, I sketched out initial ideas on how user would interact with the features inside the product. We decided it made sense to have a troubleshooting workbench where the user can find evidence suggested by the system and also have a toolbox where they can gather data manually.

Iterations Part one
Below you can see some of the early iterations and concepts. I took a look at what kind of data is available in the product, discussed with engineering on how the algorithm for determining relevant evidence works, and considered user needs.


Iterations Part Two
In the second round of iterations, some features were removed due to engineering effort and feasibility for the current release timeline.
For example, I found out from our engineering team that the three types of evidence (events, property changes, and anomalous metrics) cannot be ranked together with their current algorithm. As a result, I also had to work out how to display the evidence by category.


implementation
The final designs were created using VMware’s design system Clarity along with custom designs and components built by me. I created guides for all the new pieces for engineering to refer to during implementation and provided assets such as new icons and gradients. Since vRealize Operations Manager has both a light and dark theme, colors were considered for both. Below is a snippet of what I provided engineers:

Final Designs
Below are key screens from the final designs. They were created using Figma.

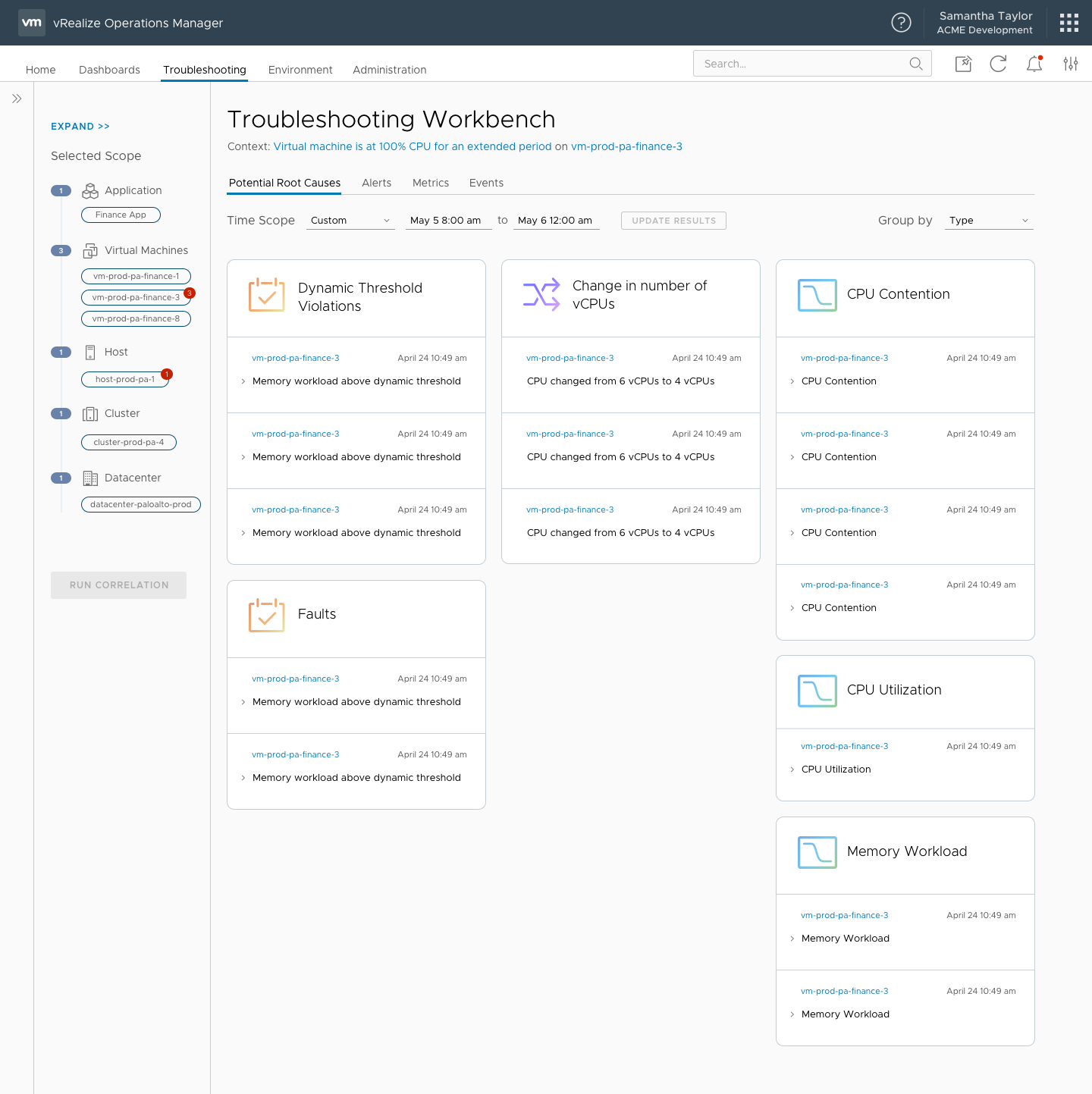
Troubleshooting workbench home page, where the user can start by searching for an object

Potential evidence discovered by system

Starting troubleshooting through an alert, with the option to launch into the troubleshooting workbench
Results
The project lasted 5 months, from the vision creation to implementation, and was released as part of vRealize Operations Manager 8.0 in October 2019. The troubleshooting functionality was first showcased at VMworld 2019 and was well received by users.
In general, troubleshooting workflows are very difficult to test because there’s never one clear path or checklist you can run through to resolve an issue; almost every case has unique pieces. However, we still wanted to get a sense of user sentiment and see if there’s anything we can do to improve it in future releases. We ran a user survey to collect feedback.
We were pleasantly surprised by the findings:

We got a few anecdotes as well, and it’s extremely rewarding to see the different we’re making and to really help our VI admins reduce their MTTR (mean time to resolution).
I resolved something that used to take me 2-3 days to solve in only 45 minutes using the new troubleshooting flow!
-vROps user
In terms of areas of improvement, some users felt the evidence surfaced was too noisy and others wanted integrations with other products to pull in a larger variety of data. We used this data to help prioritize work for the following release.
The product development team and I also jointly filed a patent for the troubleshooting work since this was a novel algorithm and method to discover evidence for resolving issues.

Future Work
Taking in the pain points from the users and considering the overall end-to-end vision we want to achieve, I continued working with product management and engineering to explore ideas for future releases.
I created design concepts for the ability to save evidence into a timeline format, to rate evidence, and to view historical data as evidence. We ran some of these ideas at a customer roundtable and got positive responses. It’s encouraging to see that we’re moving in the right direction, and we hope to one day help our users achieve a truly self-driving datacenter.